
CRF: Rating Classic Yachts
CRF: Rating Classic Yachts, From Gaffers to Square Tops
CRF; Rating Classic Yachts, From Gaffers to Square Tops
My Int’l 8-Meter design for owner/builder/sailor/friend Bruce Dyson was launched in May, 2004. Soon after, he took Pleione to Maine for their Penobscot Bay wooden boat series, where she finished 2-1 in the first two races she sailed. When she went back north to go 1-1-1 in her next three races, the locals took to referring to her as “that damned 8-meter…” Pleione’s Marblehead crew enjoyed their outsider ‘who ARE those guys’ mystique, but more importantly, they (we) were thoroughly intoxicated by a fabulous wooden boat show combined with some good competition. Certainly I was hooked on Classic racing, because after years of grand prix racing where the sole criterion for success is winning, (or not, so those who don’t win go home surly), it was enormously refreshing to see sailors value the sweep of the sheer, the gloss of the varnish, the quality of the restoration, and the sophistication of the new build, in addition to the finish positions. Of course, after decades spent comparing boat characteristics and performance potential with rating under multiple rating rules, I could not help myself, and I began to dig into the Classic Rating Formula (CRF) that was used to score the races.
CRF was first developed in the 1990’s by a group of bright classic yacht aficionados in order to facilitate racing the old boats that they loved so much. CRF filled a need – without it there would be no Classic racing today – but I was puzzled as to how it could reflect real world performance reliably when it did not assess basic parameters like draft and displacement in any direct way. It quickly became clear that in fact it couldn’t, without putting a human thumb on the scales in assigning subjective and substantial ‘Adjustments to Base Rating’. Over time, competition and growth inevitably exposed shortcomings in CRF’s original form, and frustrations emerged regarding a lack of transparency in the way that CRF’s ‘black box’ established ratings. I recall being pro-active (and presumptuous?) in offering unsolicited suggestions as to how to improve CRF early in my experience with it. Fast forward a few years, and my ‘reward’ for that input was to be named to a Technical Committee tasked with developing a new, hopefully improved, and fully transparent ‘MkII’ version of CRF for the 2017 racing season. Me and my big mouth…
Developing the basic structure of CRF MkII:
It happened that in late 2016 when the committee started its work I had some time available, so I was receptive to taking a lead role in the effort. As background, I had decades of experience dealing with the IOR, MHS/IMS/ORC,ORR, and IRC rating systems, plus the International Rule (12m’s, 8m’s etc), plus the IACC America’s Cup Rule, going all the way back to the early 1970’s. In addition, and more importantly, I had recently been contributing to the Offshore Racing Congress’ adaptation of their ORCi VPP to superyacht racing. That fleet is wildly diverse in that it ranges from light, ‘small’ (100 ft!), bulb keeled racing sloops to enormous shoal draft, ketch rigged, ‘cruise ships with sails’. My takeaway from the success of that effort was that if it was possible for a rating system to adequately model the performance effects of features unique to superyachts like huge sat nav antennae, multi-story superstructures, and a variety of rig geometries, it followed that it should be possible to account for the diversity in the classic fleet as well. The ‘Rig Factors’ that earlier versions of CRF assigned to different rig types (marconi sloops, gaff headed sloops, ketches, yawls, schooners, etc) and used in calculating ratings were a sensible approach to addressing rig variations in the Classic fleet, and they suggested the conceptually similar Keel Profile and Spar Material factors that are critical to what became ‘CRF MkII’ . But where to start with developing a rating formula that would reliably reflect the performance potential of even mainstream sloops, the low hanging fruit, let alone the inevitable outliers, without having to apply the subjective adjustments to ratings that owners found so confusing and frustrating?
When it comes to understanding sailboat performance, it’s hard to go wrong starting with Nat Herreshoff. In his Universal Rule formula he put length and sail area in the numerator, where bigger numbers generate a higher rating and imply more speed potential, and he put displacement in the denominator, where a bigger number slows rating down. With those basics in mind, another obvious ‘go to’ was the wisdom of Olin Stephens, who was instrumental in melding the sail area formulae of the CCA rule together with the hull and appendage formulae from Europe’s RORC to form the International Offshore Rule (IOR) in the early 1970’s. Before designers began distorting IOR hulls with bumps and hollows at measurement points in order to slow ratings down, the rule did a quite good job of rating ‘normal’ boats fairly, so adapting the basic format of IOR for a MkII rework of CRF seemed a sensible choice. CRF depends entirely on a literal handful of owner data declarations, with no official measurers involved, so IOR’s multiple measurements for hull depths, profile slopes, girths, etc. were obviously out the window. Still, paring the IOR down to its bare essentials based on a few critical point measurements seemed a viable approach, given that it is unlikely that an owner would make significant modifications to his 100 year old classic just to optimized to a rating rule. It is also worth noting that some of the later and most successful IOR designs reverted back to nice, clean, distortion free shapes, and that while some with the most severe bumps and hollows did rate slow, they sailed even slower. Once a simplified IOR structure had been chosen as the basic architecture of what we began to call ‘CRF MkII’, with some Universal Rule influence added, the next task was to directly address the perceived shortcomings of original CRF.
2017 CRF MkII base rating:
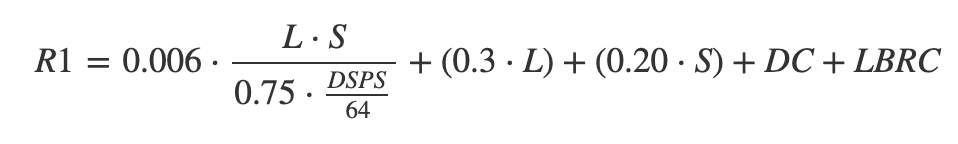
Addressing problems with original CRF:
It is well understood that length is the most basic of all sailboat performance parameters, so that given two generically similar boats of different sizes, the larger will be faster than the smaller. Further, at least at high speeds, the speed of the larger will greater than that of the smaller by an amount proportional to the square roots of their respective sailing lengths. Recognizing this fact, original CRF calculated rating based on the square root of length, which would have been fine except that CRF races are then scored using a Herreshoff style time allowance table that effectively applied the root of length (closely tied to rating) a second time. This gave bigger boats a substantial corrected time advantage over smaller boats under CRF, because their greater length was heavily discounted. To correct this size bias (and to keep all units consistent in linear feet) CRF MkII assesses length at its full value, understanding that the time allowance table then accounts for the root based speed/length proportionality. A second length related problem with original CRF was that it based its Rated Length (‘L’) on a simple 50/50 average of LOD and LWL. This worked to the disadvantage of boats with long overhangs, as their longer length on deck was seldom (if ever) immersed, even at high speeds. Recognizing that length near the waterline contributes far more to effective sailing length than length on deck, MkII uses a weighted average, with LWL weighted four times more heavily than LOD.
2017 CRF MkII formula for effective sailing length:

Beyond these length issues, there were a number of other shortcomings in original CRF that also needed to be addressed. Primary among these problems was the fact that the original formula did not address either displacement or draft in any way. These are critical performance parameters, and the fact that it did not include them meant that ‘Adjustments to Base Rating’ as large as 30% had to be applied in order to arrive at ratings that resembled reality. MkII assesses displacement directly as a primary term in base rating, as well as in both Displacement/Length and Sail Area/Displacement factors that are applied to the base rating. Draft is also assessed directly in MkII via an ‘IOR style’ Draft Correction that compares Rated Draft to a calculated Base Draft that varies with length, and that is ‘tuned’ to be typical of the Classic fleet. Rated Draft that is deeper than Base Draft speeds rating up, while draft shallower than base slows it down.
Another problem with original CRF was that while it did recognize that boats that are narrow for their length (long for their beam) tend to be fast, its Beam Ratio Factor was a step function, so that a boat falling just on the ‘narrow side’ of a step would rate significantly faster than a near sister happening to fall just slightly on the beamy side of that same step. Further, since the function was based just on LOA, it again disadvantaged boats with long overhangs. CRF MkII still includes a Length/Beam Ratio Correction in its formula for Base Rating, but it replaces the step function with a calculated Base LBR that is a reference curve fit to length beam ratios across the Classic fleet. Further, the length term in the LBRC calculations is the weighted average effective sailing length ‘L’ instead of just LOA. For a given length, LBR’s that are higher (narrower) than the base speed ratings up, while those that are lower (beamier) slow rating down.
Measuring gaff headed sails in a way that accurately reflects their actual area is very difficult, but those who developed CRF came up with a very simple and clever workaround that just uses the boom length and height of the peak halyard, and this approach is continued in MkII. However, in assessing upwind sail area, original CRF assumed that everyone sailed with a 150% genoa, and it based spinnaker area on that same assumption. This of course disadvantaged anyone who did not carry a big genoa upwind, and since it based spinnaker area on a 150% overlap headsail as well, ignoring spinnaker hoist and pole length entirely, it disadvantaged small overlap downwind as well. MkII adapts its upwind sail area calculations from the CCA-IOR model, and it does account for differences in headsail overlap. For simplicity, its assessment of spinnaker area assumes a default calculated mid girth (although this is likely to change for 2022), but it does account for actual chute hoist, pole length, and a-sail tack point. The value for rig driving force is taken as the square root of sail area (with and without spinnaker) to keep the units consistent in linear feet, and in establishing rated ‘S’ it is modified by the ‘Rig Factor’, that varies from 1.0 for a generic sloop all the way down to 0.50 (half as efficient and effective) for a schooner with gaff heads on both the main and foresail.
CRF MkII Rig Types and Dimensions: (Adapted from original CRF)
Once the basic formula for CRF MkII was established, the vital work of ‘tuning’ the embedded factors and coefficients so that the calculated ratings matched up with real world performance got underway in earnest. From the beginning, a critical development tool has been a ‘test fleet’ of boats that represents the full range of boat sizes and types participating in classic racing. The ratings generated by the new formulae for boats in the test fleet are continually vetted by comparing them with those generated by original CRF, as well as with PHRF and IMS ‘general purpose handicaps’ (GPH) when these were available and applicable. When PHRF handicaps and CRF’16 ratings for the same boat were found to differ substantially, the MkII rating for that boat typically fell in between, which suggested a useful ‘reality check’. More importantly, a number of Classic, Vintage, and SoT boats in the test fleet have been fully measured for VPP based ratings, providing some especially reliable rating benchmarks. The effects of the new formulae on relative ratings within the test fleet showed that MkII did address the perceived shortcomings in original CRF. Further, rescoring past classic events showed that the new MkII ratings did not change many finish places, and so did not disrupt the competitive balance of the current fleet unduly. Most importantly, MkII ratings did reflect the real world performance potential of boats over the full range of the classic fleet well, without the need to resort human intervention via subjective adjustments to the calculated rating. MkII is strictly declared data in, and rating out.
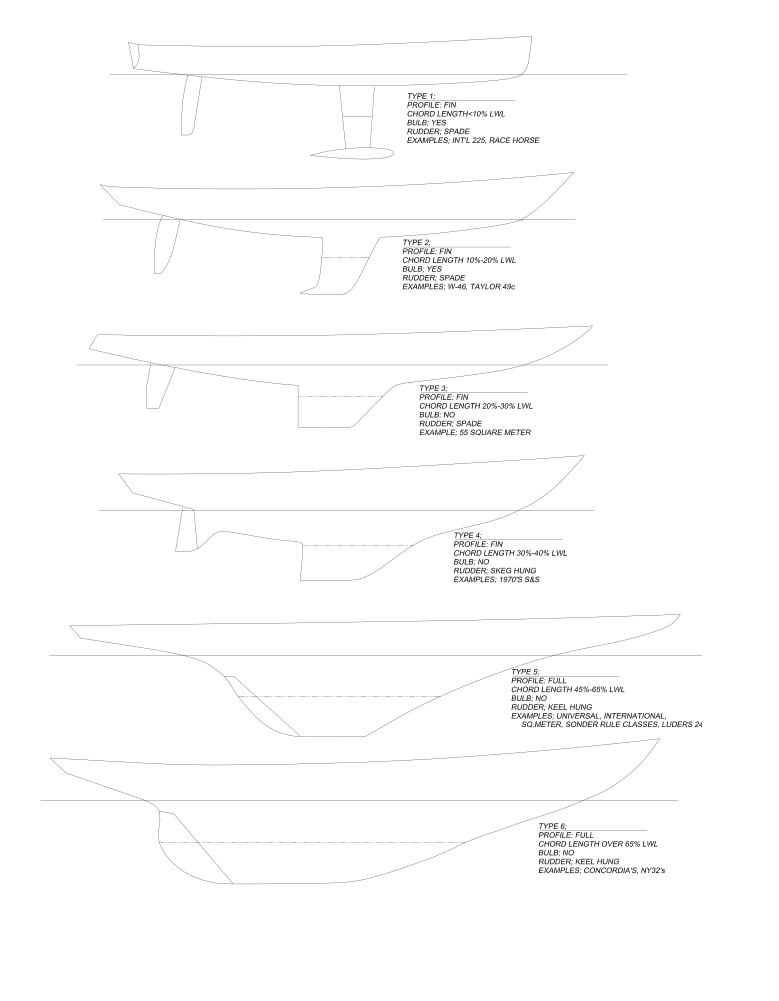
CRF Keel Types and Descriptions: One of the most critical features of CRF MkII
On-line implementation and early returns:
I started my work developing the CRF MkII formulae and factors in October of 2016, and I presented my ‘beta’ code and test fleet ratings to the Technical Committee for its review just before Christmas. However, implementing MkII as a finished, user friendly system that included a web based application process and produced certificates that were freely available on line was completely outside my skill set. After an initial plan to have USSailing administer CRF did not pan out, we were saved by a strong recommendation that we contact Blake Jackson, who had recently implemented a very successful application and certificate process for PHRF New England. Luckily Blake agreed to work with us, and had the patience to turn my Excel based algebra into on-line code that could take the data declared by owners in their applications, and perform the needed calculations. Blake also designed an attractive new CRF MkII certificate, that displayed the input data, many of the calculated outputs, and, of course, ratings, expressed in both decimal feet and in seconds/mile, both with spinnaker and without. The first 2017 MkII certificates were issued on May 11, and over 300 were issued during that first season. What remained was to see how well the new ratings matched up with reality, and whether they would be accepted and embraced by the participants.
With my name so directly associated with the new rating formula, I often said that I needed to go into witness protection on rollout, and I was not entirely joking. I fully expected some blowback and controversy, partly because both typically come with any change to anything, and partly because there would inevitably be incremental winners and losers when owners absorbed the impact of new ratings. I didn’t get protection, but I did happen to be starting a vacation in Iceland when the results from the first races scored with MkII were posted, which was the next best thing. If the NYYC Annual Regatta results looked good, I could enjoy the rest of my vacation. If not, maybe I could hole up in Reykjavik until I could fix the problems. Luckily, the WiFi in our B&B was good, and so were the results. The courses were short, but multiple boats corrected out within a minute of each other, and when the regatta was over a fin keel, separated rudder Spirit of Tradition boat beat an 80 year old full keel NY 32 by just 1/2 point. I took mini victory lap around Iceland.
The rest of the 2017 season went well for CRF MkII in that the race results looked good, and there were no angry mobs with lanterns and pitchforks. Instead, most of the dock talk was positive, and those who had questions could refer to the website, where all of the formulae and factors used in calculating ratings were posted, along with answers to FAQ’s. (See https://www.classicyachts.org/ratings/) However, an in-depth look back at 2017 results that focused on boats that were regular participants and were similarly well prepared, well equipped and well sailed did raise some caution flags. First, long, narrow, race-oriented boats (eg. Universal and International Rule boats) appeared to be advantaged relative to the rest of the fleet. Second, deep draft, especially among some centerboarders, seemed to be disadvantaged against more normal draft. Third, the vintage staysail schooner Fortune corrected out way too well, way too often. And finally, there were some anomalies in the owner declarations for keel type and LWL vs displacement for some boats. Overall, it was a quite good initial roll out of an entirely new system tasked with rating an unusually diverse fleet of boats, and our firm mandate for full transparency was met. There were definitely some refinements needed, however.
Refinements for 2018:
It might seem that tweaking the Length/Beam Ratio Correction (long narrow race boats advantaged) and Draft Correction (deep draft disadvantaged) would be a simple process, but it very much was not. The problem was unintended consequences; there is a discrete Rig Factor for staysail schooners, so speeding up the ratings of staysail schooners was easy, as it had no effect on other ratings. Changing the LBRC, on the other hand, can speed up the ratings of the targeted long, narrow racy boats that were judged to be advantaged, but it would also speed up the ratings of other long narrow cruisers that were handicapped fairly with no change. Changes to the Draft Correction in isolation proved to be equally unworkable for the same reason. The secret sauce was an in depth review of a full range of performance parameters, identifying type characteristics, and adjusting a subtle combination of factors and coefficients in addition to the targeted LBRC and DC in order to effect the ratings of just the targeted types. A simultaneous challenge was to have ratings still reliably reflect real world performance, and not upset the competitive balance across the rest of the fleet. The goals were eventually (and painstakingly!) achieved, but perhaps the most important aspect of the refinements made for the 2018 season was setting the precedent that there would likely be changes made to CRF annually. Having the expectation that yearly changes will be routine can be a powerful disincentive to teams optimizing to the rule too aggressively (loophole hunting?), and it ended any debate about why certificates need to be renewed each year; they need to stay in synch with annual changes.
A careful analysis of 2018 Classic race results under the revised version of MkII showed that a very healthy mix of boat sizes, types, and launch dates were routinely scored with corrected times within a few sec/mi of each other, suggesting that it did provide generally fair racing for much of the fleet. As evidence of this, Sonny (1935 S&S 53), Blackfish (2017 49 ft SOT), Leaf (1944 Luders 24), Siren (1936 S&S NY32), and Neith (1907 Herreshoff 53) were all similarly well prepared and well sailed, but they are radically different in size, age, and general characteristics, so it is impressive that they were so closely matched under CRF. However, digging more deeply into the 2018 race result details did show that inevitably, further fine tuning of the formulae and factors was needed.
More tweaking for 2019:
The review of the 2018 race results suggested three areas that needed refinement for 2019. First was the fact that split rigs (yawls, ketches and schooners) did not correct out as well as similarly well-equipped and well sailed sloops often enough, so for 2019 the drive force for their sail area was reduced slightly via their ‘Rig Factors’. Second, light boats that were also narrow for their length appeared to be disadvantaged, partly because the Length/Beam Ratio Correction was now slightly too aggressive, but mainly due to their low stability. Having some assessment of stability is critical to accurately modeling sailboat performance, and it is directly measured for the IOR, IMS/ORC, and ORR rules. That is not in the cards for the ‘no measurers, all declared data’ world of CRF, but not addressing stability at all put boats with high stability (such as 12 meters) at a distinct advantage relative to the fleet norm, and boats with unusually low stability at a similar disadvantage. Without the benefit of actual inclining data, the best stability related information then available was displacement, beam, draft, and a calculated default crew weight. These were combined to calculate an estimate of stability on which a ‘Stability Correction’ could be based, but for 2019 it could only be sized to nudge ratings incrementally in the right direction since it was based on such limited data. An important step was asking for a ballast weight declaration in the application for a 2019 certificate that could be used for a much improved stability estimate for 2020.
One issue that had been anticipated from the very beginning of the MkII initiative was that some boats with modern race boat characteristics would inevitably appear in the Spirit of Tradition class, and that the formulae and factors that were developed for the generic Classic fleet would not be able to fully capture their performance potential. This discrepancy was monitored by comparing CRF MkII ratings of modern boats with their VPP generated General Purpose Handicaps (GPH). The most obvious difference, beyond appendage details, is that the sterns typical of modern boats are much broader and more powerful than the norm in the Classic fleet, which provides them with an extra gear in breeze, especially off the wind. As a first step towards addressing this feature, the application for 2019 certificates for boats with design dates of 1990 or later required a declaration for deck beam at the aft end of their waterline, which reflects volume aft (and implied speed potential) in the same way that after girths do in the International and IOR rules. This added data declaration was dubbed ‘Bm10’, and when it is greater than a threshold value, the excess is used as an increment added to the effective sailing length, resulting in a faster rating for broad sterned moderns.
Unfortunately, the 2019 classic racing season involved a large number of weather related curveballs that made it unusually hard to draw many reliable conclusions regarding real world performance vs CRF MkII ratings. Still, a very healthy mix of boat sizes, types, and launch dates did end up on event podiums, and the races that had more straightforward conditions did suggest some avenues towards further improvements to the 2019 MkII formulae and factors. A useful way of quantifying how well a rating system models real world performance is to compare rated performance (eg CRF rating in sec/mi + 535) with actual as-sailed performance (elapsed time in seconds divided by distance sailed). Several observations emerged from this ‘as sailed vs rating’ reality check for the 2019 season.
CRF MkII becomes CRF 2020;
The most obvious conclusion from the 2019 season was that modern race boats, including Outlier, were not rated fast enough under the 2019 version of CRF MkII even with the broad stern increment added to the weighted average length. This was anticipated, as the ratings of a ‘shadow’ test fleet of modern boats (eg Farr 40, J-122, Club Swan 42, etc) had been monitored throughout the development of the MkII formulae. Additionally, boats that were designed and built as focused racers (like the Universal and International Rule boats, L-24’s, etc) had had an advantage in stability over dual purpose boats with more weight in cruising amenities and less in ballast. Part of the performance vs rating gap for modern designs was addressed in CRF 2020 via the ‘Keel Factor’ for their Type 1 keels, to better reflect their advantages in wetted area, aspect ratio and stability. For both the moderns and the older racers, the ballast and rigging material data gathered with the 2019 certificate applications was incorporated into an improved and more powerful Stability Correction for 2020, that more accurately reflected this difference in stability and upwind performance potential.
Finally, boats with canoe sterns had been rated too fast under CRF, which has to rely on point measurements for LOA and LWL in assessing effective sailing length. There are only a handful of canoe sterned hulls in the Classic fleet (eg Arion/Galavant, Angelita, Dagger, Zingara, Rosinante’s), and they all needed rating relief. An analysis of available lines plans suggested that the effective sailing length of canoe sterned hulls is typically about 95% of their point-to-point LWL measurement compared to that of the more rounded afterbodies typical of most Classics. For CRF 2020 the LWL for canoe sterned boats was reduced by 5% in calculating their effective sailing length ‘L’
A Covid constrained 2020 season:
A number of Classic events were canceled or shortened in 2020, so there were not nearly as much useful race data to analyze as there had been in previous years. However, the limited data that was available suggested that CRF 2020 did a quite good job of allowing a wide variety of boat sizes and types to get on the podium when the course content approximated the 1/3 upwind, 1/3 reaching and 1/3 downwind that it is intended to address, or when races that varied widely from that target were rescored with an appropriately adjusted course length. One useful observation was that in the 2020 Eggemoggin Reach Regatta, small boats rated w/o chutes finished 1st and 3rd in fleet either side of Leaf in 2nd who was rated w/spinnaker, which suggested that CRF 2020’s spinnaker vs no spinnaker rating deltas did an acceptable job of reflecting their performance potential differences when sailing with or without spinnakers. Scoring spinnaker and non-spinnaker entries together is not recommended as a first option for event organizers, as it can go badly wrong if the course content is predominantly upwind or down, but it can an acceptable option when class sizes would be too small if the two were scored separately. Another helpful observation was that the CRF 2020 adjustments made to the Stability Correction and the Type 1 Keel Factor did speed up the ratings of Outlier and of the moderns in the ‘shadow test fleet’ appropriately, so that they now correspond much more closely with their VPP generated GPH ratings. Overall, no serious size, age, boat type or rig type biases stood out in the data gathered from the 2020 race analysis, so no substantive changes were made to CRF 2020 ratings in implementing CRF 2021.
One look back and another forward:
As of this writing, CRF MkII was rolled out almost exactly four years ago, ready or not. Happily it proved to be ready enough, and it has provided a lot of close and fair racing in the time since. The fact that the dock talk has been focused on the racing rather than on the ratings suggests that the sailors agree that MkII has been an important step forward for Classic racing. As the ‘coder in chief’ I did not have to go into witness protection, but getting MkII to work as well as it has, including its annual refinements, did not come easy. I probably could have developed an entire new design in the hours that I have spent on CRF, but I have no regrets, and I take a lot of satisfaction from how well it has matched on-the-water reality. I did not do it alone, of course! Several of my fellow Technical Committee members have the expertise to do the work that I did, and others were much more closely connected with the participants than I was, and so could keep me grounded in what mattered most to the end users. Certainly the reworking of CRF would not have happened without the leadership and steady hand of our long time committee chair Simon Davidson, or the experience and perspective of Steve White, one of the several originators of CRF, and the major domo of wooden boat racing in Maine. The MkII ‘user experience’ from roll out through CRF 2021 definitely would not have been as positive without the skill, patience, and hard work of Blake Jackson, our web based ‘implementer in chief’. And finally, Adam Langerman carefully (and patiently!) checks all the owner data declarations, and issues the certificates.
Going forward, Simon Davidson has decided to step back from CRF, and take a well-deserved rest. I now chair a great Technical Committee, that serves as part of the Classic Yacht Owners Association (CYOA) whose Executive Committee is, in turn, chaired by our own Steve White. CRF 2021 certificates are already being issued, and everyone is anxiously looking forward to getting back on the water after a covid constrained 2020 season. CRF 2021 is essentially identical to CRF 2020 (we now refer to it by year to track the refinements), but there are issues on our 2021 ‘watch list’. One is the current ‘Draft Correction’ for deep draft, especially as it is applied to centerboards. Another is setting some standards for how far alterations to an existing boat can go before she should be bumped into another Division, and this will become more critical now that the CYOA Challenge Series awards are based on Division assignments. Already in the works for CRF 2022 is the inclusion (to be required for newly built sails only, but optional for all) of mainsail and spinnaker widths in sail area calculations, and addressing newly developed free flying ‘tweener’ sails, whose mid width falls in what was once the ‘no sail zone’ between 50% and 75% of its foot length. The work continues, so stay tuned…